이번에는 GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding이라는 논문을 리뷰해보도록 하겠다. 해당 논문은 GLUE benchmark를 제안하는 논문이며, 이 GLUE는 GPT, BERT와 같은 pre-trained language model의 성능을 테스트할 때 사용된다.
원문 링크는 다음과 같다.
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
For natural language understanding (NLU) technology to be maximally useful, both practically and as a scientific object of study, it must be general: it must be able to process language in a way that is not exclusively tailored to any one specific task or
arxiv.org
Introduction
인간이 언어를 general, flexible, robust하게 이해하는 것과는 달리, 대부분의 NLU(Natural Language Understanding) model들은 specific 한 task를 위해 설계되었으며, out-of-domain의 data에서는 성능이 잘 나오지 않는다.
만약 단순히 입력과 출력의 표면적인 대응관계를 감지하는것을 넘어서는, linguistic understanding을 가지는 model을 만들어야 한다면, 다른 domain에서 다양한 linguistic task를 실행하는 unified model을 만드는 것이 매우 중요하다.
이러한 unified model을 만드는 방향의 연구를 촉진시키기 위해, 본 연구에서는 GLUE(General Language Understanding Evaluation) benchmark를 제시한다.
GLUE benchmark는 QA(Question Answering), Sentiment analysis, Textual entailment를 포함하는 NLU task의 모음이며, test 하는 model의 evaluation, comparison, analysis를 위한 온라인 플랫폼과 연동된다.
(해당 온라인 플랫폼은 아래와 같다.)
GLUE Benchmark
The General Language Understanding Evaluation (GLUE) benchmark is a collection of resources for training, evaluating, and analyzing natural language understanding systems
gluebenchmark.com
또한 GLUE는 model의 architecture에서 single-sentence와 sentence-pair input을 처리하여 이에 대응하는 prediction을 만들어내는 것 이외에는 아무런 제약을 두지 않는다.
GLUE에는 training data가 풍부한 task들도 있지만, training data의 개수가 제한된 task도 있으며, training set과 test set의 genre와 match하지 않는 task도 존재한다.
이러한 특징은 GLUE가 sample-efficient learning과 다양한 task에서 효과적인 knowledge-transfer를 촉진하는 방법으로 언어적 지식을 학습하는 model을 선호하게끔 한다.
GLUE에 포함되어 있는 dataset들은 기존에 존재하던 dataset들로부터 기인하였다고 하며, dataset중에서 4개는 benchmark가 공정하게 사용되는지 확인하는 데 사용되는 private-held test data를 제공한다.
(private test data로 evaluation하기 위해서는 결과를 위에 소개된 온라인 플랫폼에 제출해야한다.)
이에 더불어, GLUE는 model이 학습한 유형을 이해하고, 언어적으로 의미 있는 solution strategies를 장려하기 위해 set of hand-crafted analysis example을 제공한다. 해당 dataset은 model이 robust 하게 task를 해결하려면 반드시 다뤄야 하는 common challenge(use of world knowledge and logical operator)에 초점을 맞추도록 설계되었다.
지금까지 나온 내용들을 정리하자면 다음과 같다.
- GLUE는 9개의 NLU task 모음이며, 각각의 task는 annotated dataset으로 구축되었으며 다양한 genre, dataset size, degrees of difficulty를 다루도록 선별되었다.
- privately-held test data를 기반으로 하는 online evaluation platform과 leaderboard가 존재하며, model-agnostic 하여 architecture의 제약을 두지 않는다.
- expert-constructed diagnostic evaluation dataset을 제공한다.
Tasks
GLUE는 9개의 english sentence understanding task로 이루어져 있다. 해당 task들은 다양한 domain, data의 양, 난이도를 총망라한다. GLUE의 목적이 일반화 가능한 NLU system의 개발의 촉진이기 때문에, 저자들은 GLUE benchmark에서 model이 좋은 성능을 내려면 해당 model이 약간의 task-specific 한 요소를 남겨놓는 상태에서 모든 task에 걸쳐 상당한 양의 knowledge(trained parameter)를 공유해야 하도록 설계하였다.
GLUE에서 제공하는 task들에 대해, pre-training을 하지 않거나 별도의 외부 source를 이용한, 각각의 task를 위한 single model을 train 하여 GLUE benchmark를 통해 evaluate 하는 것도 가능하다. 그러나 저자들은 GLUE의 몇몇 task는 data의 개수가 제한된 data-scarce task이기 때문에, 이러한 task에서는 위와 같은 방법이 제 성능을 발휘하지 못할 것이라고 예측한다.
그러면 GLUE에서 제공하는 task들에는 어떤 것들이 있을까? task들의 대략적인 정보를 담고 있는 자료를 본 다음, 하나씩 살펴보도록 하겠다. GLUE의 task들은 다음과 같다.

GLUE의 task는 크게 나눠보면 다음과 같이 나뉘게 되는데,
- Single-Sentence Tasks
- Similarity and Paraphrase Tasks
- Inference Task
차례대로 하나씩 살펴보겠다.
Single-Sentence Tasks
CoLA
Corpus of Linguistic Acceptability(CoLA)는 언어 이론과 관련된 책과 저널 기사에서 추출된 english acceptability judgement로 이루어진 dataset이다. 각각의 example은 해당 영어 문장이 문법적인지 아닌지에 대해 annotated 된 sequence of words이다.
(아래의 도표는 CoLA의 example들이다.)
CoLA에서는 evaluation metric으로 unbalanced binary classification에 대해 -1과 1 사이의 값(0은 uninformed guessing에 대한 성능을 나타냄)으로 evaluate 하는 Matthews correlation coefficient를 사용한다.
GLUE에서는 CoLA의 저자로부터 private label을 얻은 standard data set을 사용하며, test set에서 in-of-domain section과 out-of-domain section의 조합에서의 단일 성능 수치를 report 한다.
SST-2
Stanford Sentiment Treebank(SST-2)는 영화 리뷰 sentence와 해당 sentence에 대한 sentiment의 human annotation으로 이루어져 있다.
SST-2로 수행하는 task는 주어지는 sentence에 대해 sentiment를 예측하는 것이다. GLUE에서는 positive와 negative의 두 가지 class만 사용하며, sentence-level label만 사용한다.
SST-2의 예시는 다음과 같다.

Similarity and Paraphrase Tasks
MRPC
Microsoft Research Paraphrase Corpus(MRPC)는 온라인 뉴스로부터 추출된 sentence pair와, 해당 sentence pair를 구성하는 sentence가 의미상으로 같은 sentence인지에 대한 human annotation으로 이루어져 있다.
MRPC는 imbalanced data이기 때문에(68% positive), accuracy와 f1 score 둘 다 사용하여 report 한다.
QQP
Quora Question Pairs(QQP)는 Question answering 웹사이트인 Quora에서 추출한 question pair의 모음이다.
MRPC의 경우처럼, sentence가 의미상으로 같은 sentence인지에 대한 human annotation으로 이루어져 있고 imbalanced data이기 때문에 (63% negative) accuracy와 f1 score 모두 사용하여 report 한다.
또한, GLUE에서는 QQP의 원작자로부터 받은, private label을 가진 standard test set을 사용하며, 이러한 test set은 training set과는 다른 label distribution을 보인다.
QQP의 예시는 다음과 같다.

STS-B
Semantic Textual Similarity Benchmark(STS-B)는 news headline, video and image captions, natural language inference data에서 추출한 sentence pair의 모음이다.
각각의 pair에 대해서 1부터 5까지의 유사도 점수를 매긴 human-annotated label이 대응되며, STS-B를 통해 진행하는 task는 해당 유사도 점수를 predict 하는 것이다. 또한 이를 Pearson and Spearman correlation coefficients로 evaluate 한다.
예시는 다음과 같다.
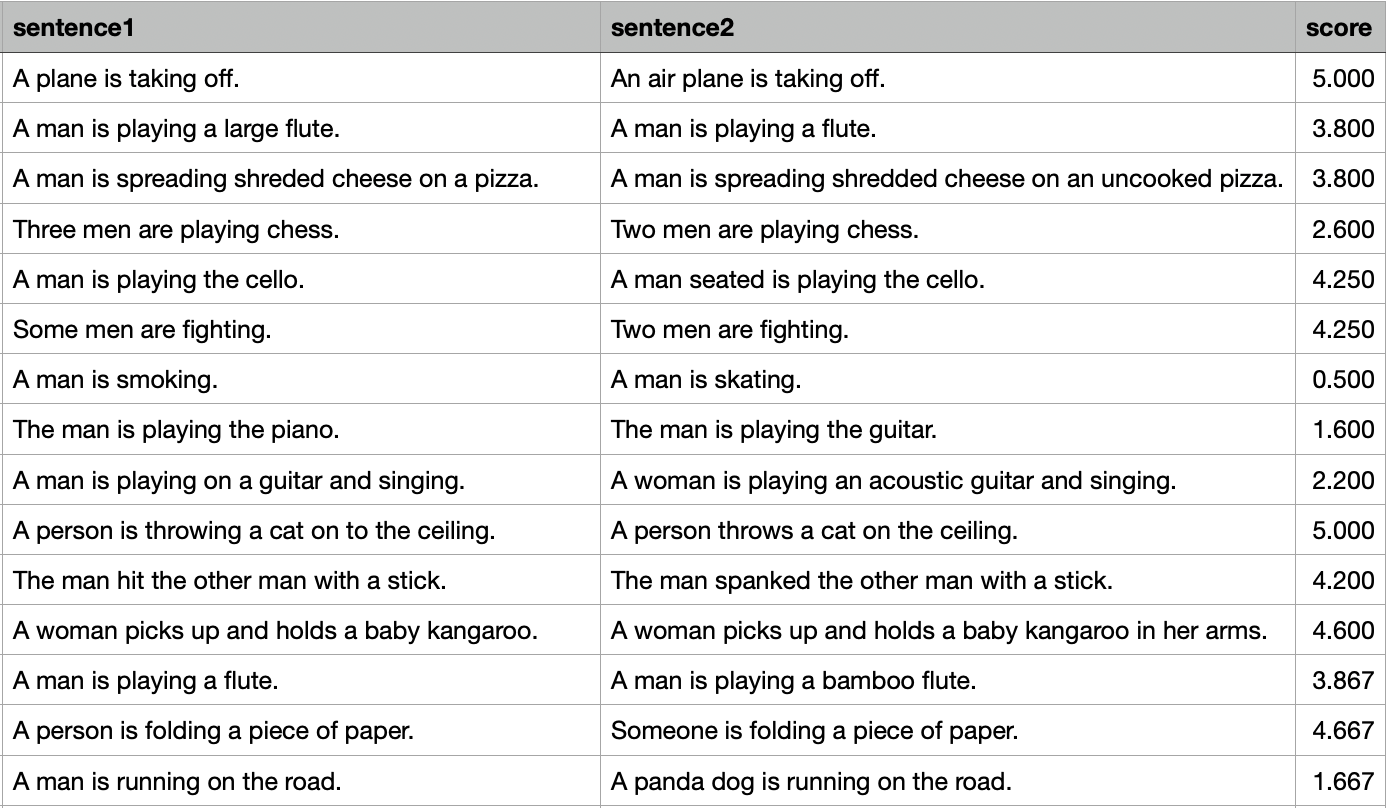
Inference Task
MNLI
Muti-Genre Natural Language Inference Corpus는 crowd-sourcing으로 구축된 textual entailment annotation이 있는 sentence of pair이다.
MNLI로 수행하는 task인 textual entailment는, premise(전제)와 hypothesis(가설)가 주어지며, premise(전제)가 hypothesis(가설)를 entail 하는지 predict 하는 task이다.
premise(전제)가 hypothesis(가설)를 entail 하면 entailment, contradict 하면 contradiction, 둘 다 아니면 neutral의 label로 predict 한다.
(여기서의 entail은 "함의"의 뜻이며, premise가 사실일 때 hypothesis의 사실을 보장하는 것을 의미한다. contradict의 경우에는 premise와 hypothesis가 서로 모순된다는 의미이다.)
Premise sentence들은 transcribed speech, fiction, government report를 포함한 10개의 다른 source로부터 수집되었다. 이 논문에서는 나오지 않지만, hypothesis를 구축할 때에는 수집된 premise를 바탕으로 crowd-sourcing을 진행하였다.
아래는 MNLI dataset의 예시이다.

QNLI
Question-answering NLI(QNLI)는 Stanford Question Answering Dataset(SQuAd)를 변형시킨 dataset이다.
우선, Stanford Question Answering Dataset(SQuAd)에 대해 알아보자. SQuAD는 question-paragraph의 pair로 구성된 question-answering dataset이다. paragraph는 자기 자신과 대응되는 question에 대한 answer를 포함하고 있다.
(paragraph는 wikipedia로부터 추출되었으며, question과 answer는 crowd-sourcing을 통해 생성되었다.)
SQuAD를 통해 수행하는 task는 QA task인데, QNLI는 SQuAD dataset을 변환하여 sentence pair classification으로 변환한다. 먼저, question과 이에 대응하는 paragraph를 이용하여 pair of sentence를 형성하고, 이렇게 형성된 pair of sentence들 중에서 lexical overlap(어휘적 중복)이 낮은 쌍을 필터링한다. (어휘적 중복이 낮은 쌍을 제거하는 것이 아닌, 중복이 낮은 쌍을 선별한다)
이러한 수정은 model이 옳은 answer를 선택할 필요를 제거하지만 answer가 input속에 항상 있을 것이라는, 또한 lexical overlap(어휘적 중복)이 신뢰할 수 있는 단서일 것이라는 "단순화된 추정"도 제거해주는 효과가 있다.
이후, 수정된 QNLI dataset을 통해서 paragraph가 question에 대한 answer를 포함하고 있는지에 대한 classification task를 수행하게 된다.
다음은 QNLI의 예시이다.

RTE
Recognizing Texual Entailment(RTE) dataset은 annual textual entailment challenges로부터 추출되었다. 본 연구에서는 RTE1, RTE2, RTE3, RTE5를 혼합하였다고 밝힌다. (이 dataset들은 뉴스와 wikipedia로부터 구축되었다.)
또한 원문 dataset인 RTE들은 위에서 소개한 MNLI와 같이 entailment, neural, contradiction의 3개 class로 구분되어있었는데, GLUE에서의 RTE는 neutral과 contradiction을 not_entailment로 묶어 entailment와 not_entailment의 2개의 class로 수정하였다.
RTE의 예시는 다음과 같다.
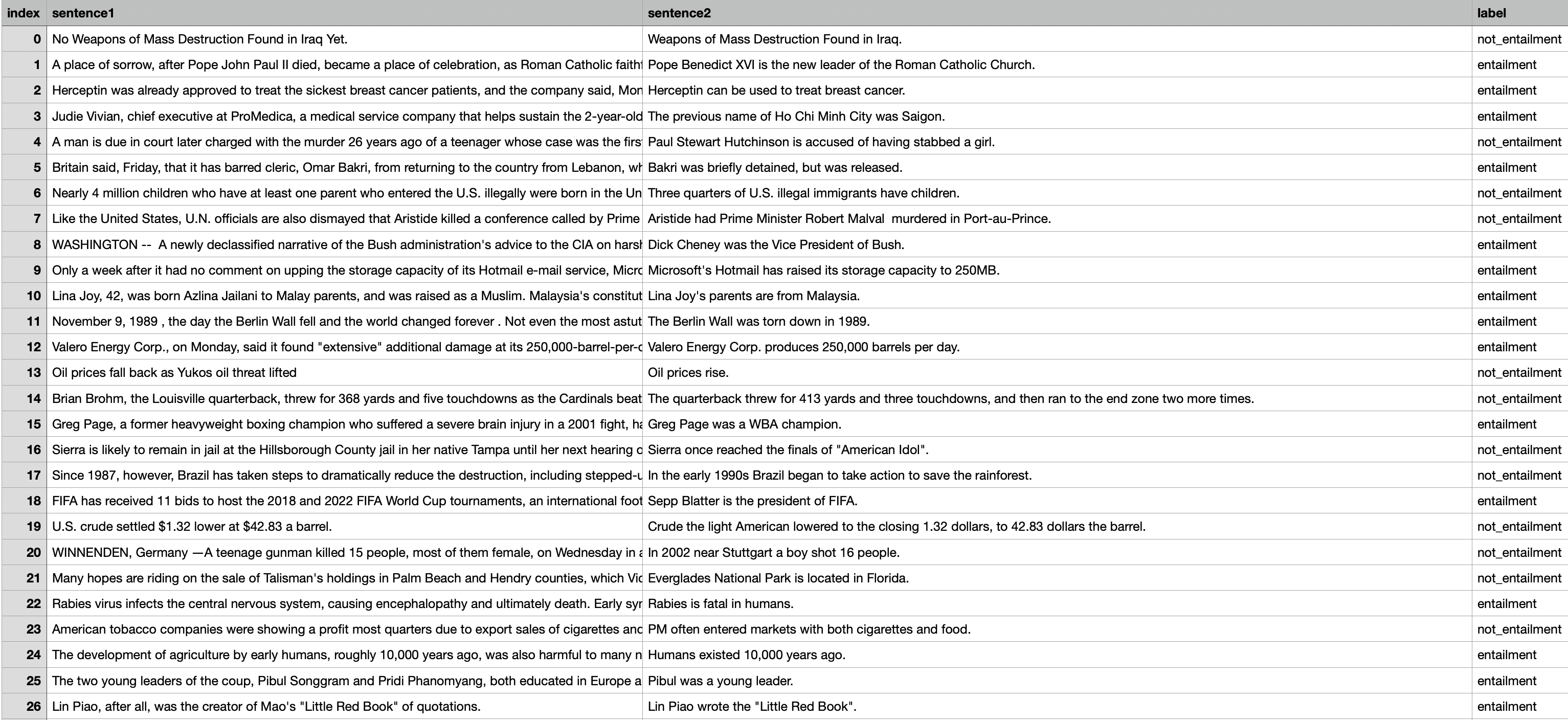
WNLI
Winograd NLI(WNLI)는 Winograd Schema Challenge의 변형이다. (QNLI와 비슷한 느낌이다.)
Winograd Schema Challenge는 reading comprehension task이다. 이 reading comprehension task란, model이 pronoun(대명사)가 있는 문장을 읽고 해당 pronoun(대명사)의 referent(참조)를 선택 목록 중에서 선택해야 하는 task인 것이다.
이러한 reading comprehension task를 sentence pair classification task로 변환한다. 이를 위해 각 문장의 pronoun을 가능한 각각의 referent로 바꾸고, 원본 sentence와 함께 sentence of pair를 만든다.
이후, 원본 sentence가 pronoun이 대체된 문장을 entail 하는지 predict 하는 task를 수행한다. (이때, entailment, not_entailment의 이진 분류이다.)
GLUE에서 WNLI dataset은 original corpus의 저자들이 privately 하게 공유한 small evaluation set을 사용한다.
WNLI의 training set이 balanced data인 것에 비해, test set은 imbalanced data이다. 또한, data quirk로 인해 development set은 adversarial(적대적)하여 간혹 training example과 development example이 공유되는 경우가 발생하는데, 이때 만약 model이 training example을 기억하고 있다면 development example에서는 잘못된 label을 예측하게 된다.
(즉, training set에 overfitting 되어있으면 development set에서는 성능이 크게 하락할 수 있다.)
아래는 WNLI의 예시이다.
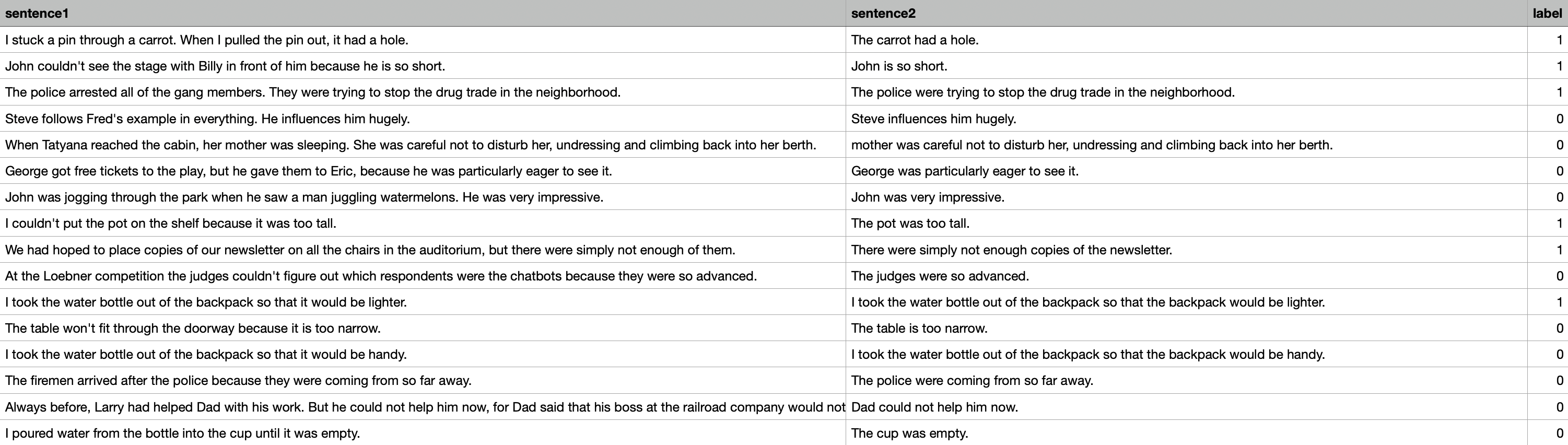
Evaluation
model을 GLUE benchmark로 evaluation 하기 위해서는 제공되는 task에 대한 test data에 대해 model을 통해 나오는 결과를 GLUE 웹사이트에 업로드하여 점수를 책정받아야 한다. (이는 Kaggle이나 Dacon을 생각해보면 쉽게 이해할 수 있다.)
GLUE benchmark 웹사이트는 task별 score와 해당 task들의 macro-average score를 보여주고, 리더보드 상에서의 순위를 결정한다. accuarcy와 f1 score를 같이 사용하는 task의 경우, 전체 task의 macro-average score를 구할 때에는 task에 대한 두 metric의 unweighted average를 해당 task의 score로 계산한다.
추가적으로, GLUE benchmark 웹사이트에서는 diagnostic dataset의 fine-grained result와 coarse-grained result도 제공한다.
Diagnostic Dataset
GLUE에서는 model의 성능 분석을 위해 manually-curated 된 small test set을 제공한다. Main benchmark가 application 중심의 distribution of example을 반영하는 것과는 달리, diagnostic dataset은 저자들이 model이 capture 하기에 중요하고 흥미롭다고 생각하는 pre-defined set of phenomena에 중점을 둔다.
pre-defined set of phenomena은 다음과 같다.
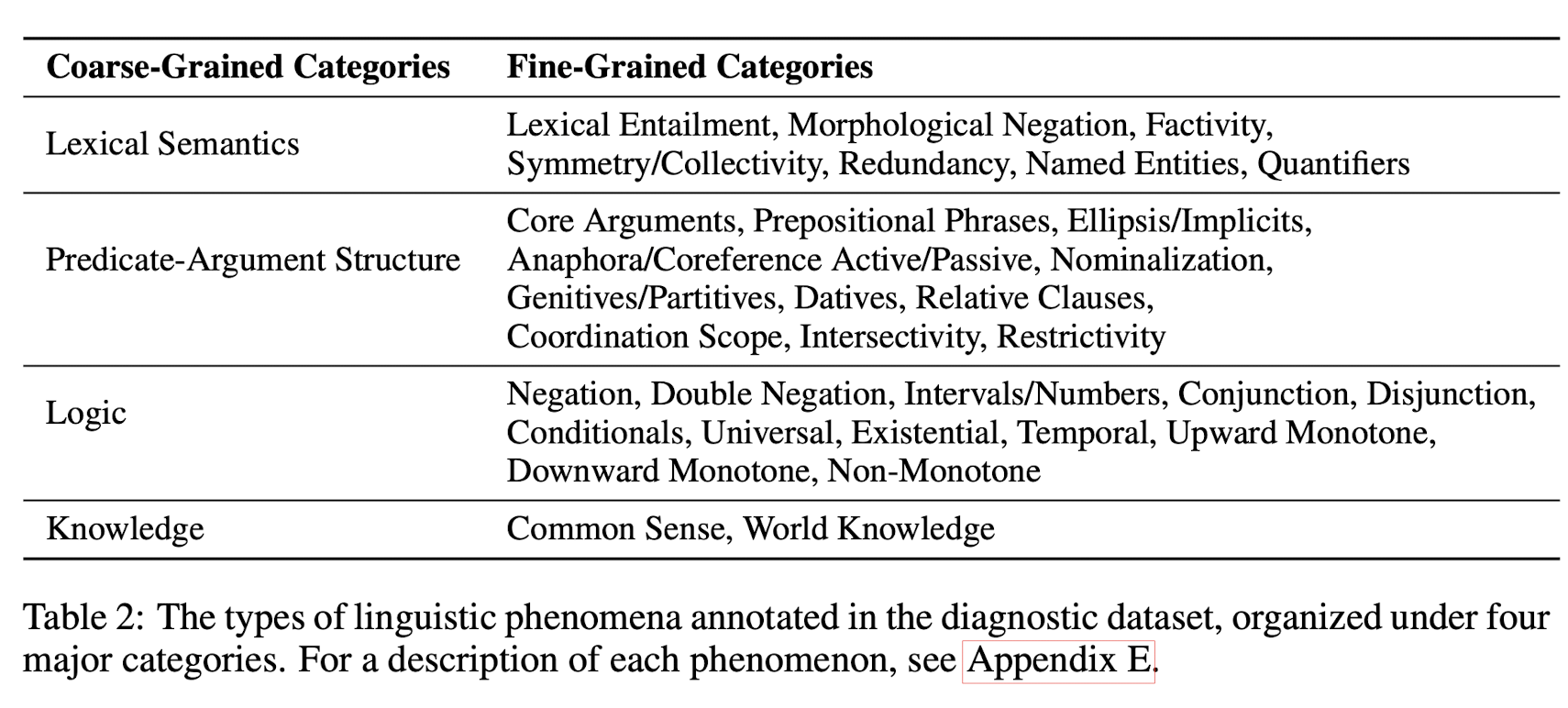
각각의 Diagnostic example은 NLI(Natural Language Inference) sentence pair와 증명된 phenomena로 이루어진다.
또한 저자들은 이러한 diagnostic dataset이 다양한 linguistic phenomena에 대한 예제를 생성하였고, 여러 domain에서 자연스럽게 발생하는 sentence들을 기반으로 하였기 때문에 합리적으로 다양한 dataset이라고 주장한다.
dianostic example의 예시는 다음과 같다.
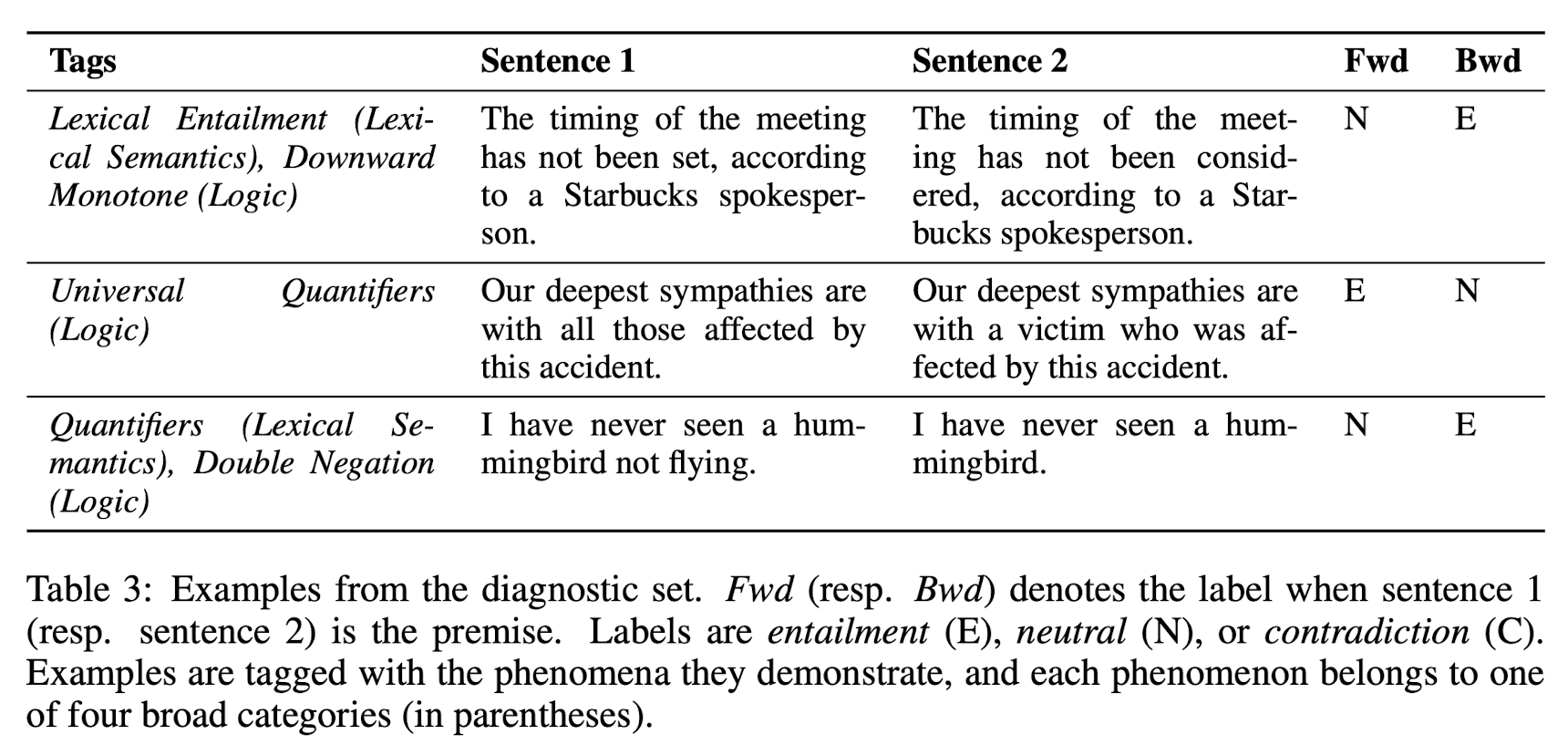
이에 대해 간단히 설명하자면, 우선 위에서 언급한 것처럼 NLI sentenc pair와 tag로 구성되어있고, 그 밖에 Fwd와 Bwd가 보인다.
이에 대해 설명을 하자면, Fwd는 sentence 1이 premise이고 sentence 2가 hypothesis일 경우의 label이고, Bwd는 그와 반대로 sentence 2가 premise이고 sentence 1이 hypothesis인 경우이다. 또한, label은 E(entailment), N(neutral) 그리고 C(contradiction)로 구성된다
저자들은 diagnostic set을 model의 전반적인 성능이나 downstream application에서의 generalization을 반영할 것으로 생각하지 않는다고 말한다. 그러면서, diagnostic set은 benchmark가 아닌 error analysis, qualitative model comparison, development of adversarial examples를 위한 분석 도구라고 덧붙인다.
최근 다양한 PLM의 성능 지표가 되어버린 GLUE에 대해 다뤄보았다. GLUE가 발전한 SuperGLUE도 존재하는데, 이것도 추후 다른 게시글에서 다뤄볼 예정이다.
논문에서는 이 게시글에서 다룬 내용 이외에도 baseline model에 GLUE benchmark를 적용한 결과와, appendix에서 pre-defined set of phenomena에 대한 자세한 설명을 덧붙였다. 이 부분은 본 게시글에서는 생략하도록 하겠다. 추후 해당 내용에 대한 필요성이 발생하면 추가해보려고 한다.




댓글