이번 게시물에서는 google에서 발표한 논문인 Query Expansion by Prompting Large Language Models 에 대해 다뤄보겠다. 본 논문은 retrieval system의 성능을 향상시키기 위한 기법 중 하나인 query expansion에 LLM을 활용해본 연구를 다룬다.
원문 링크는 아래와 같다
https://arxiv.org/abs/2305.03653
Query Expansion by Prompting Large Language Models
Query expansion is a widely used technique to improve the recall of search systems. In this paper, we propose an approach to query expansion that leverages the generative abilities of Large Language Models (LLMs). Unlike traditional query expansion approac
arxiv.org
Introduction
Query expansion은 검색 시스템에서 recall을 향상시키기 위해 사용되며, original query에 additional term을 추가해줌으로써 이루어진다. 이러한 expanded query는 original query에서는 lexical overlap이 없어서 고려되지 못했던 relevant document를 고려해줄 수 있게끔 한다.
전통적인 query expansion 방법론들의 경우, 일반적으로 pseudo-Relevance Feedback(PRF)기법을 기반으로 한다. PRF기법은 original query로 retrieve된 set of retrieved document를 “pseudo-relevant”로 취급하고, 새로운 query terms들을 추출하는데 사용한다.
그러나, PRF-based approach들은 top-k의 retrieve된 document들을 query와 relevant하다고 가정한다. 사실, initial retrieved document들의 경우 original query와 완벽히 align되진 않으며, 특히 query가 짧거나 모호한 경우에는 이러한 현상은 더 심해진다. 이러한 이유들로 인해 PRF-based approach들은 initial set of retrieved document가 relevant하지 않은, bad document들이 retrieve된다면 최종적으로 좋지 않은 결과를 산출하게 된다는 문제점이 존재한다.
본 연구에서는 LLM을 query expansion에 사용한다. LLM의 text를 generate하는 능력을 활용하여 유용한 query expansion을 만들어내게끔 활용하는 방법론을 제안한다. 특히, 저자들은 LLM에 prompt하여 original query에 대해 다양한 alternative and new term을 생성하는 방법을 연구했다고 한다.
즉, PRF document나 lexical knowledge base에 의존하지 않고 LLM으로부터의 knowledge에 의존하여 query expansion을 진행한다는 것이다. 아래는 이 과정을 나타내는 figure이다.

저자들은 본 연구가 아래와 같은 contribution을 가지고 있다고 이야기한다
- Query expansion을 위한 다양한 형태의 prompt를 정리하였다(zero-shot, few-shot, CoT)
- CoT prompt가 가장 좋은 성능을 내는 것을 확인했으며, 이는 CoT prompt는 answer를 query expansion에 도움이 되는 많은 keyword로 분해하기 때문이라고 가정하였다
- 다양한 model size에 대한 성능 실험을 진행하였으며, query expansion에 LLM을 활용하는 방법론의 한계를 제안하였다
Methodology
저자들은 query expansion을 다음과 같이 정의하였다
Query q가 주어질 때, relevant document를 retrieve하는데 도움을 주는 expanded query q’를 생성
그리고, 본 연구에서는 이러한 query expansion을 LLM으로 진행하였다고 한다. LLM의 output이 verbose할 수 있기에, 저자들은 original query를 5번 반복하여 상대적인 중요도를 높였다고 한다. 이는 아래와 같다
이어서, 저자들은 본 연구에서 아래와 같은 8개의 prompt를 사용했다고 밝힌다
- Q2D → Query2Doc의 few-shot prompt이며, model로 하여금 query에 대답하는 passage를 출력하라고 함
- Q2D/ZS → Q2D의 zero-shot 버전
- Q2D/PRF → Q2D/ZS와 같이 zero shot prompt이지만, query에 대한 top-3 PRF document형태의 extra content를 포함하고 있음
- Q2E → Q2D와 비슷하지만, few-shot exemplar로 document 대신 query expansion term example들을 제공한다
- Q2E/ZS → Q2E의 zero-shot 버전
- Q2E/PRF → Q2E/ZS와 같이 zero shot prompt이지만, Q2D/PRF와 같이 PRF document 형태의 extra content를 포함하고 있음
- CoT → Zero-shot CoT prompt
- CoT/PRF → CoT prompt와 비슷하지만 query에 대한 top-3 PRF document형태의 extra content를 포함하고 있음
Zero-shot prompt들(Q2D/ZS, Q2E/ZS)은 instruction과 query로만 구성된 가장 간단한 prompt이다. Few-shot prompt들(Q2D, Q2E)의 경우, in-context learning을 위한 추가적인 example들을 포함하고 있다. CoT prompt들의 경우, instruction이 model로 하여금 response를 step-by-step으로 분해하여 verbose한 output을 얻게끔 구성되어있다. Pseudo-Relevance Feedback(/PRF) prompt들은 top-3 retrieved document를 추가적인 context로 사용하여 model에 입력해준다.
이러한 prompt들의 예시는 아래와 같다
Experiments
LLM-based query expansion의 효과성을 입증하기 위해, 저자들은 MS-MARCO와 BEIR을 통해 성능 평가를 진행하였다고 한다. Retrieval system으로는 BM25를 사용하였으며, default BM25 parameter를 사용했다고 한다.
Baseline
LLM-based query expansion과 성능을 비교할 방법론들로 아래와 같은classical PRF-based query expansion 방법론들을 채택했다고 한다
- Bo1: Bose-Einstein 1 weighting
- Bo2: Bose-Einstein 2 weighting
- KL: Kullback-Leibler weighting
Language Models
저자들은 prompt들에 대해 아래와 같은 model들에 적용해보며 실험을 진행하였다고 밝힌다
- Flan-T5-Small (60M)
- Flan-T5-Base (220M)
- Flan-T5-Large (770M)
- Flan-T5-XL (3B)
- Flan-T5-XXL (11B)
- Flan-UL2 (20B)
Metrics
성능 평가의 metric으로는 Recall@1K, MRR@10, NDCG@10을 사용했다고 한다
Results
MS-MARCO Passage Ranking
MS-MARCO passage ranking task에 대한 결과는 아래와 같다
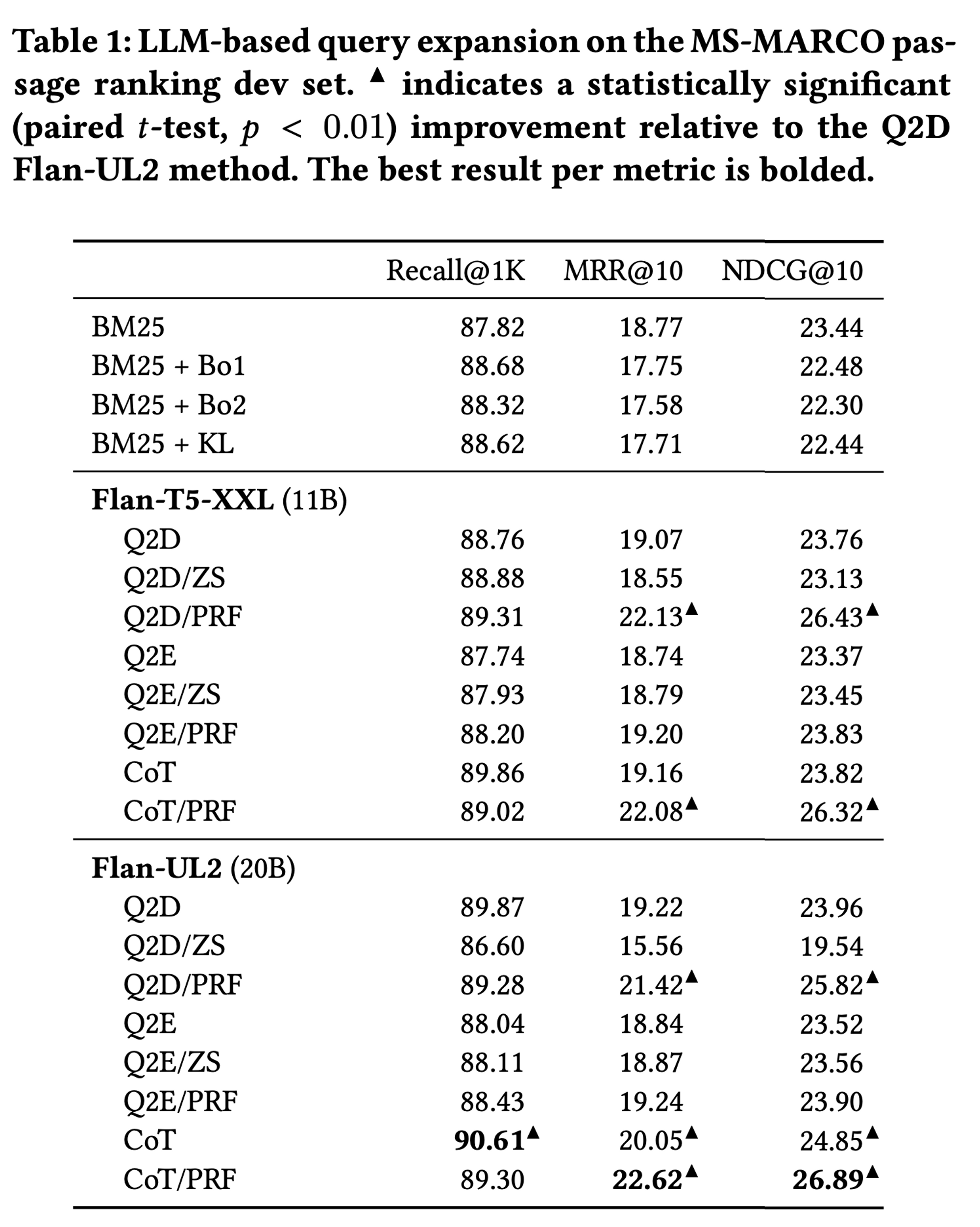
Bo1, Bo2, KL과 같은 classical query expansion baseline들의 경우, Recall@K에서는 standard BM25에 비해 성능 향상이 있지만, MRR@10, NDCG@10과 같은 metric에서는 성능이 저하된 것을 확인할 수 있다.
이어서, LLM-based query expansion 방법론들을 살펴보자. 전반적으로 봤을 때, LLM-based query expansion의 경우 prompt type에 따라 성능 변화가 크다는 것을 알 수 있다.
그 중에서, Query2Doc prompt들의 경우엔 classical approach들에 비해 모든 metric에서 성능 향상이 이루어진것을 확인할 수 있다. 이는 classical query expansion 방법론들이 recall을 올리기 위해 top-heavy ranking metric에서의 성능 하락을 감수해야했던 것과는 다른 양상이다.
가장 좋은 성능을 낸 prompt는 CoT prompt들이다. 저자들은 이러한 결과에 대해 CoT가 만드는 verbosity가 query expansion에 유용한 potential keyword들을 포함하고 있기에 발생하는 것이라고 추측한다.
마지막으로, PRF document들을 query에 추가해주는 것이 top-heavy ranking metric들에서 매우 큰 성능 향상을 이뤄낸다는 것을 확인할 수 있다. 저자들은 이에 대해, LM이 이미 relelvant passage들을 포함하고 있을 수 있는 PRF document들에 대해 효과적으로 distilling하고, 그 결과로 promising한 keyword들을 출력하기에 이러한 결과가 나왔을 것이라 추측한다.
BEIR
저자들은 BEIR benchmark의 dataset들에 대해서도 성능 측정을 진행하였다. 결과는 아래와 같다
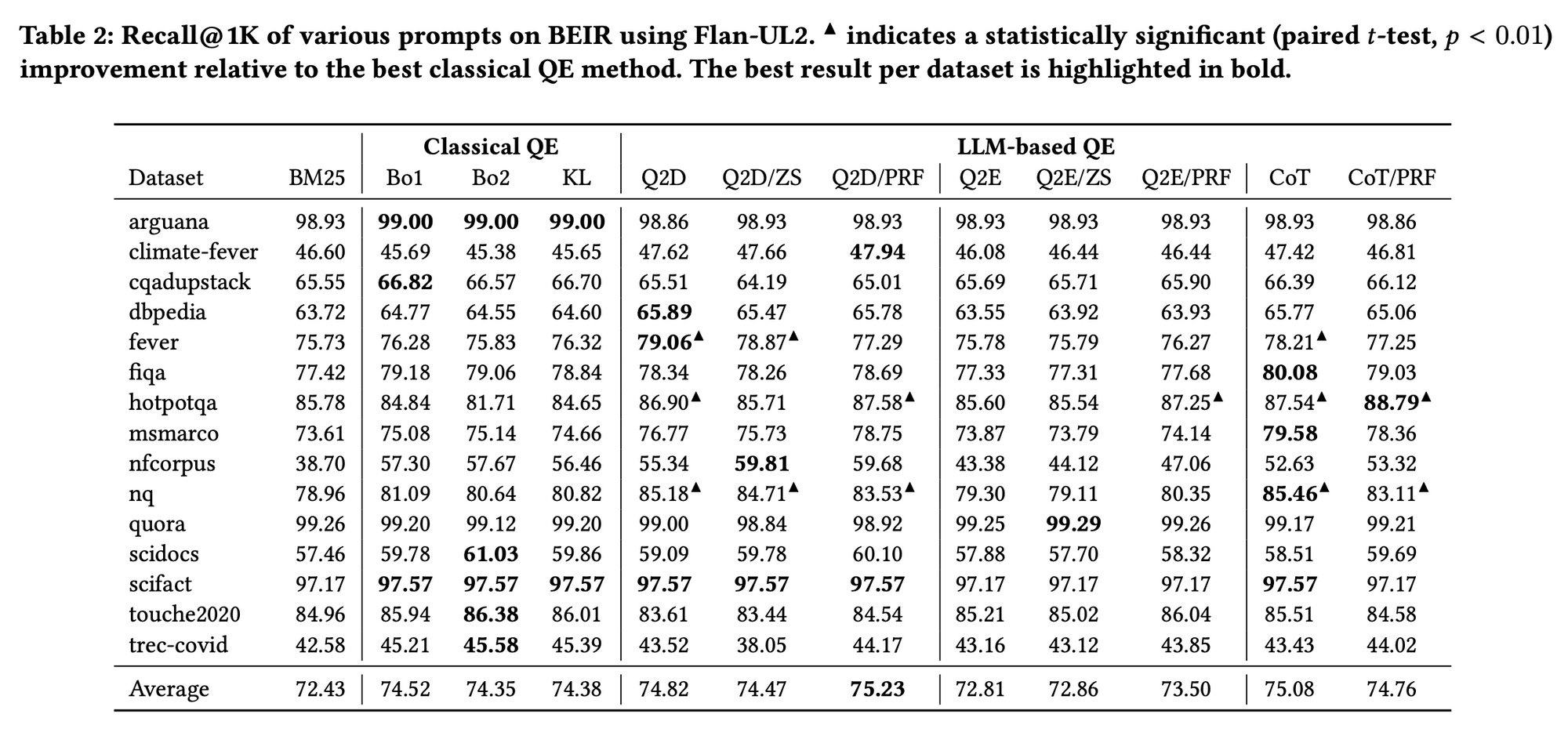
결과에 대해 살펴보자. 먼저, classical PRF-based query expansion 방법론들은 여전히 잘 작동한다는 것을 알 수 있다. 특히, academic and scientific한 domain의 dataset에서 잘 작동하는 것을 확인할 수 있다. 이와는 반대로, general-purpose LLM은 이러한 domain에 대한 useful domain knowledge가 존재하지 않기에 이러한 dataset들에 대해 좋은 성능을 내지 못한것으로 보인다
이어서, 저자들은 question-answering 형식의 dataset(fiqa, hotpotqa, msmarco and nq)에서 LLM approach가 더 유용하다는 사실을 제시한다. 이에 대해, 저자들은 LM이 query에 대해 relevant한 answer를 생성하고, 이러한 generated relevant answer가 효과적으로 relevant passage를 retrieve하기에 이러한 결과가 나왔을 것이라 추측한다
The Impact of Model Size
저자들은 LLM의 size를 다르게 해가며 성능 비교를 진행하였다. 이에 대한 결과는 아래와 같다
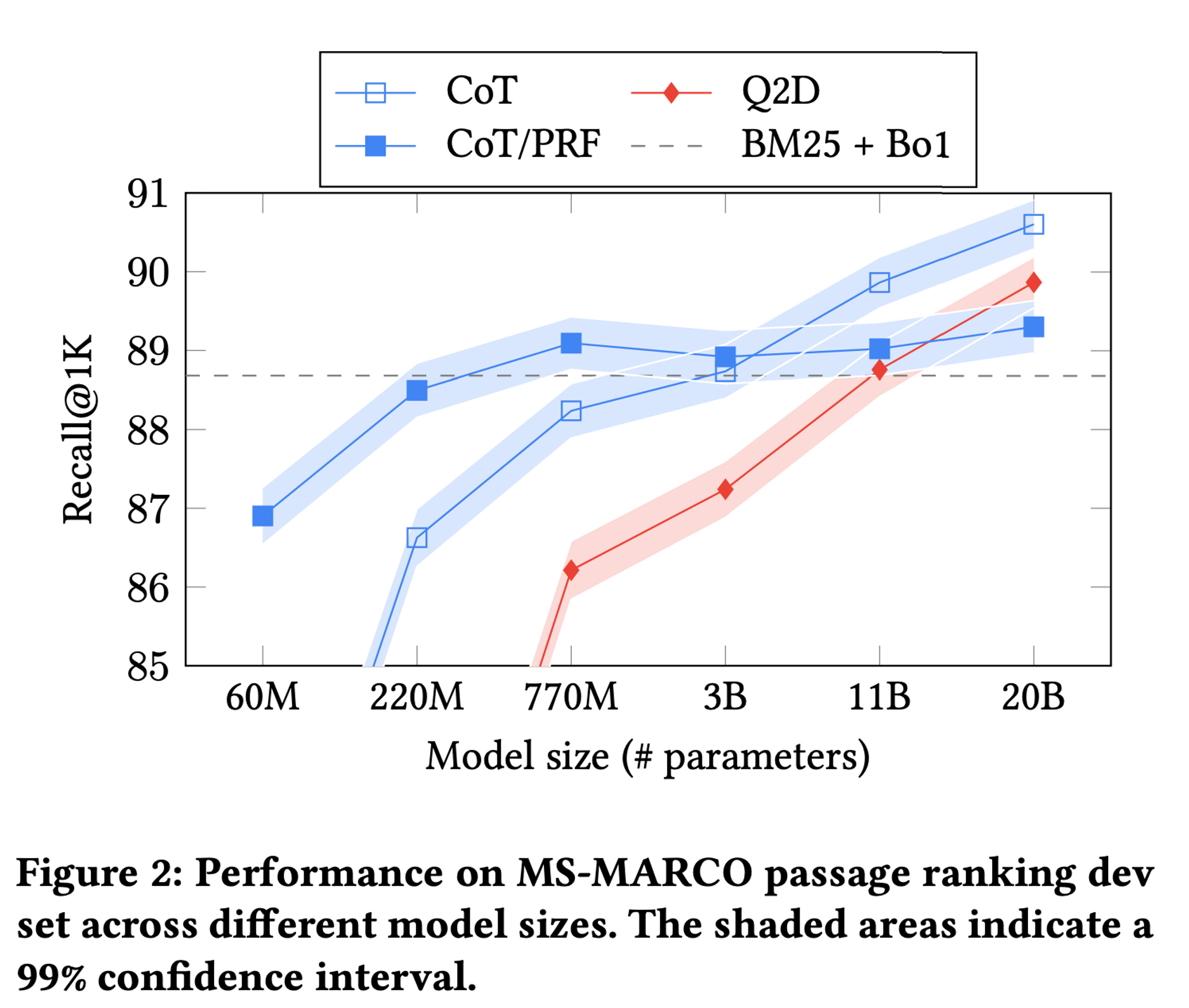
전반적으로, LLM의 size가 커질수록 더 좋은 성능을 낸 것을 확인할 수 있다. 이어서, Q2D 방식은 최소 11B의 size가 되어야만 baseline인 BM25 + Bo1의 성능을 따라잡을 수 있었지만, CoT prompt의 경우 3B의 size만으로도 BM25 + Bo1의 성능을 따라잡을 수 있었다.
CoT/PRF의 경우 작은 model size에서는 좋은 성능을 보였지만, model size가 커질수록 다른 방법론에 비해 성능이 낮음을 확인할 수 있다. 저자들은 이에 대해 PRF document가 주어지면, model이 제공된 document에만 집중하여 model의 창의성을 제한하기 때문이라고 추측한다. 그러나, CoT/PRF은 770M model size까지는 가장 좋은 성능을 보이며, larger model이 제한되는 search setting에서는 좋은 선택지가 될 수 있다.




댓글